
Hace un par de años vivimos un boom de los bots, principalmente de bots conversacionales, pero se veía como la afirmación de que ya estábamos preparados para automatizar todo. En mi opinión estamos lejos de eso, pero aunque no estemos preparados para los bots, sí que deberíamos convertirnos todos en cyborgs.
Un bot (abreviatura de robot), es un sistema que se encarga de hacer cosas que antes sólo podían hacer los humanos.
Un cyborg (cíborg en castellano), es un sistema que mezcla a los bots y las personas.

Ejemplos de que no estamos preparados para la automatización total hay muchos, aunque probablemente uno de los casos más llamativos, fue ese bot de Microsoft que se convirtió en un troll de Twitter.
Hay otros mucho más impactantes, como los accidentes provocados por los conductores de Tesla que se desentienden de los controles tras conectar el piloto automático. Tesla advierte repetidamente que no estamos preparados para esto, y que una compañía que se centra tanto en la automatización (de fábricas, cargadores, etc.) crea que aun no estamos preparados es muy significativo.
Esto no quiere decir que la automatización sea mala, es muy buena y aunque requiera una inversión, reduce tiempos a futuro. Sin embargo, la automatización a día de hoy aun requiere de supervision.
Por ejemplo, en un chat de asistencia técnica se pueden automatizar los pasos iniciales y sencillos como pedir al cliente sus datos para identificarlo y una descripción del problema, y luego ir proponiéndole al operador textos para ayudar al cliente, de tal modo que este no tenga que teclear y solo elegir el que más se ajusta al problema del cliente actual. Esto le puede permitir manejar 10 incidencias en el tiempo en el que antes hacía 1, pero manteniendo el control.
Mantener el control y no cedérselo a ciegas a un programa es muy importante. Puede que el programa acierte el 99% de las veces, pero el 1% restante puede resultar muy dañino, por lo que creo que a día de hoy no se puede confiar al 100%.
Esto es algo que se ha visto repetidas veces en redes sociales, en los que bots (o personas que actúan como tales) se encargan de responder a personas y meten garrafalmente la pata.
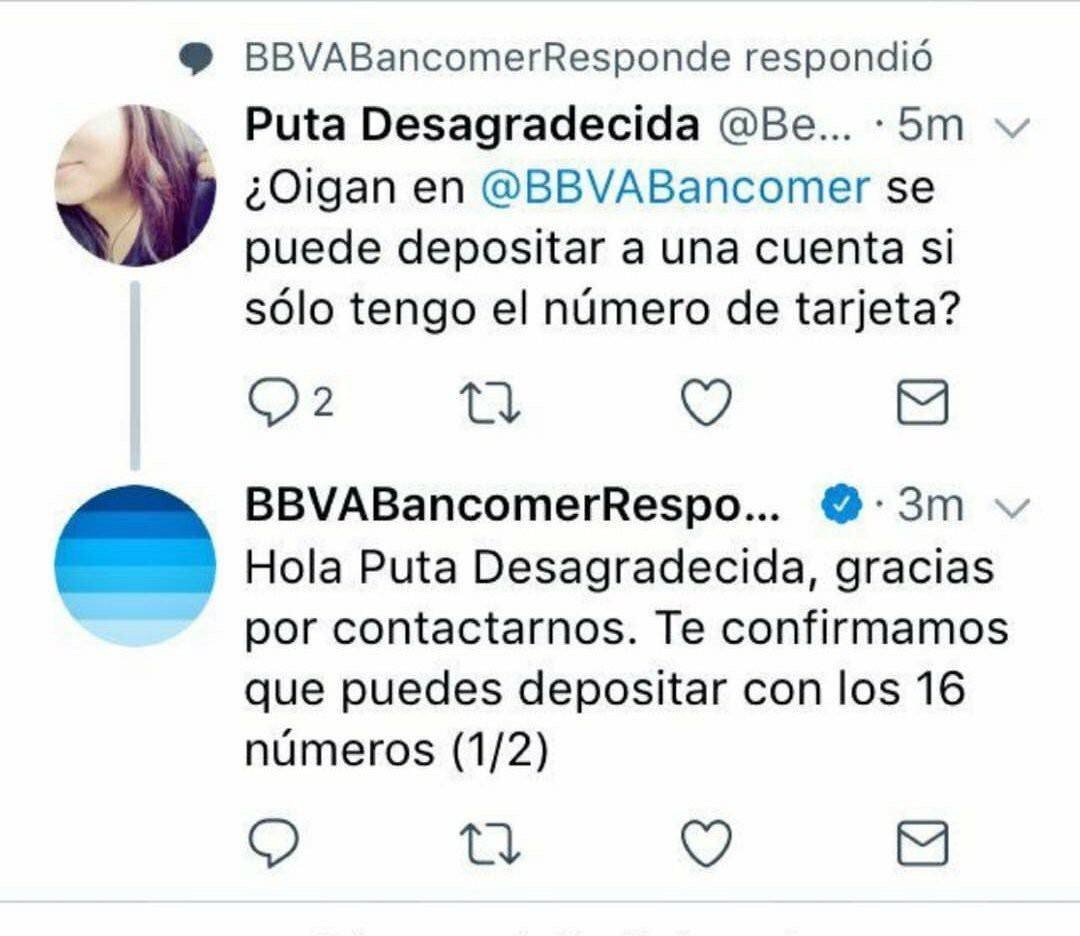
Por tanto, siempre que se vaya a ahorrar tiempo de un modo sustancial mi recomendación suele ser automatizar, pero automatizar para tener cyborgs y no bots.


