Gestiono equipos, proyectos y productos tecnológicos. Aporto soluciones creativas a grandes problemas, mezclando las metodologías y tecnologías más modernas.
Email design differs from web design because the result is not going to be shown in a web browser. Your design is going to be shown in an app: a desktop app, a mobile app, or a web app (like gmail.com or outlook.com). For this reason, the user interaction is different and the elements of HTML and CSS that you can use in your design are not the same.
If you have to design an email, you can be inspired by others’ designs.
AARRR, also known as The Pirate Metrics or The Pirate Framework, is the acronym for Acquisition, Activation, Retention, Referral, and Revenue. They are the simplest metrics that you have to consider in your funnel when going to build a business.
If you can read Spanish you could read my very own explanation about AARRR. There, you can also see Dave McClure’s speech (in English) who is the originator of this.
As they are simple metrics you don’t need a complex system to analyze them. You can use a single page canvas.
Nowadays, there are a lot of different applications of AI models that can be applied to change any field. Look at music. It is a very «traditional» one where someone creates a song and someone plays a song using some devices to create sound. How AI can change that process?
There are models that can compose songs, like «Great Balls» that was created using algorithms.
WebRTC (Real-Time Communications) is a communication way between 2 (or more) browsers without a server doing the job. It allows, for instance, to make video streaming, radio broadcasting stations, chats, or real-time edition apps.
Some weeks ago, at the beginning of the lockdown in Spain, I did a fork from another project to create World Base Chat, a tool to meet your neighbors online. It allows you to chat with your neighbors, the ones you know and the ones you don’t.
A bit of history
When the lockdown started, I encouraged the use of Next Door. This is a platform that allows neighbors to be in touch, make groups, offer and request help… However, some users said to me that this is requesting a lot of information and that’s true.
I wanted a way to talk to people from my town to know, for instance, if I can help them with something. But, I also wanted the possibility to talk to people from NYC, New Delhi, and other locations to ask them how is the situation there. I wanted the capacity to ask people at the origin of the information in a time full of fake news.
I forked another project to build, spending only two days, the seed of World Base chat, a web app to meet your neighbors.
There are some users using the app, so I think that it could be a real thing.
World Base Chat
It is not too beautiful, but it owns the functionalities that everybody needs to stay in touch with their neighbors.
Functionalities of World Base Chat
It allows anonymous users to chose a location to chat with anybody connected to the same location or the regions that contain it. So, if you choose Madrid (the city), you can chat with people in Madrid (the city and the region) but also in Spain and in the World chat. Everybody is in the World chat because all the people are on the planet or orbiting around.
You can also create a group linked to any location. You can create a group for your neighborhood. A group to contact your friends from the bowling alley. You can create a group for your University campus or for the basketball court. Yes, you can create a group for whatever you want and share the link to spread the new meeting point.
You can also see some ‘Top hosts’ that are currently active, and the data from Wordlometer related to coronavirus, in order to avoid fake news.
I know that this is very basic functionality, but this bus just started its trip and I am thinking about the next stops while doing some little improvements.
Next stops
I did some tests and got some data, and I think that the bigger next stop is private chats with the possibility to add voice and/or video to the conversation. I am starting to validate this and I trust that it is going to be a changemaker.
There are other nice-to-have like beauty and/or custom user names, maybe a registry, an emoji keyboard, drawing open graph information when people share a link… but my bid is for video chat. What do you think?
I would love read your feedback, just here or in theWorld Base Chat.
2018 has finished with a lot of innovations. It brought a lot of awards for papers about several disciplines of Computer Science at different conferences this year. Here we have the abstract of some of them:
This paper proposes and evaluates Memory-Augmented Monte Carlo Tree Search (M-MCTS), which provides a new approach to exploit generalization in online realtime search. The key idea of M-MCTS is to incorporate MCTS with a memory structure, where each entry contains information of a particular state. This memory is used to generate an approximate value estimation by combining the estimations of similar states. We show that the memory based value approximation is better than the vanilla Monte Carlo estimation with high probability under mild conditions. We evaluate M-MCTS in the game of Go. Experimental results show that MMCTS outperforms the original MCTS with the same number of simulations.
Recurrent neural network grammars (RNNGs) are generative models of (tree,string) pairs that rely on neural networks to evaluate derivational choices. Parsing with them using beam search yields a variety of incremental complexity metrics such as word surprisal and parser action count. When used as regressors against human electrophysiological responses to naturalistic text, they derive two amplitude effects: an early peak and a P600-like later peak. By contrast, a non-syntactic neural language model yields no reliable effects. Model comparisons attribute the early peak to syntactic composition within the RNNG. This pattern of results recommends the RNNG+beam search combination as a mechanistic model of the syntactic processing that occurs during normal human language comprehension.
Voice User Interfaces (VUIs) are becoming ubiquitously available, being embedded both into everyday mobility via smartphones, and into the life of the home via ‘assistant’ devices. Yet, exactly how users of such devices practically thread that use into their everyday social interactions remains underexplored. By collecting and studying audio data from month-long deployments of the Amazon Echo in participants’ homes-informed by ethnomethodology and conversation analysis-our study documents the methodical practices of VUI users, and how that use is accomplished in the complex social life of the home. Data we present shows how the device is made accountable to and embedded into conversational settings like family dinners where various simultaneous activities are being achieved. We discuss how the VUI is finely coordinated with the sequential organisation of talk. Finally, we locate implications for the accountability of VUI interaction, request and response design, and raise conceptual challenges to the notion of designing ‘conversational’ interfaces.
Relevance estimation is among the most important tasks in the ranking of search results because most search engines follow the Probability Ranking Principle. Current relevance estimation methodologies mainly concentrate on text matching between the query and Web documents, link analysis and user behavior models. However, users judge the relevance of search results directly from Search Engine Result Pages (SERPs), which provide valuable signals for reranking. Morden search engines aggregate heterogeneous information items (such as images, news, and hyperlinks) to a single ranking list on SERPs. The aggregated search results have different visual patterns, textual semantics and presentation structures, and a better strategy should rely on all these information sources to improve ranking performance. In this paper, we propose a novel framework named Joint Relevance Estimation model (JRE), which learns the visual patterns from screenshots of search results, explores the presentation structures from HTML source codes and also adopts the semantic information of textual contents. To evaluate the performance of the proposed model, we construct a large scale practical Search Result Relevance (SRR) dataset which consists of multiple information sources and 4-grade relevance scores of over 60,000 search results. Experimental results show that the proposed JRE model achieves better performance than state-of-the-art ranking solutions as well as the original ranking of commercial search engines.
In large-scale distributed systems, node crashes are inevitable, and can happen at any time. As such, distributed systems are usually designed to be resilient to these node crashes via various crash recovery mechanisms, such as write-ahead logging in HBase and hinted handoffs in Cassandra. However, faults in crash recovery mechanisms and their implementations can introduce intricate crash recovery bugs, and lead to severe consequences.In this paper, we present CREB, the most comprehensive study on 103 Crash REcovery Bugs from four popular open-source distributed systems, including ZooKeeper, Hadoop MapReduce, Cassandra and HBase. For all the studied bugs, we analyze their root causes, triggering conditions, bug impacts and fixing. Through this study, we obtain many interesting findings that can open up new research directions for combating crash recovery bugs.
Fairness in machine learning has predominantly been studied in static classification settings without concern for how decisions change the underlying population over time. Conventional wisdom suggests that fairness criteria promote the long-term well-being of those groups they aim to protect.
We study how static fairness criteria interact with temporal indicators of well-being, such as long-term improvement, stagnation, and decline in a variable of interest. We demonstrate that even in a one-step feedback model, common fairness criteria in general do not promote improvement over time, and may in fact cause harm in cases where an unconstrained objective would not.
We completely characterize the delayed impact of three standard criteria, contrasting the regimes in which these exhibit qualitatively different behavior. In addition, we find that a natural form of measurement error broadens the regime in which fairness criteria perform favorably.
Our results highlight the importance of measurement and temporal modeling in the evaluation of fairness criteria, suggesting a range of new challenges and trade-offs.
Mobile apps have become ubiquitous. For app developers, it is a key priority to ensure their apps’ correctness and reliability. However, many apps still suffer from occasional to frequent crashes, weakening their competitive edge. Large-scale, deep analyses of the characteristics of real-world app crashes can provide useful insights to guide developers, or help improve testing and analysis tools. However, such studies do not exist — this paper fills this gap. Over a four-month long effort, we have collected 16,245 unique exception traces from 2,486 open-source Android apps, and observed that framework-specific exceptions account for the majority of these crashes. We then extensively investigated the 8,243 framework-specific exceptions (which took six person-months): (1) identifying their characteristics (e.g., manifestation locations, common fault categories), (2) evaluating their manifestation via state-of-the-art bug detection techniques, and (3) reviewing their fixes. Besides the insights they provide, these findings motivate and enable follow-up research on mobile apps, such as bug detection, fault localization and patch generation. In addition, to demonstrate the utility of our findings, we have optimized Stoat, a dynamic testing tool, and implemented ExLocator, an exception localization tool, for Android apps. Stoat is able to quickly uncover three previously-unknown, confirmed/fixed crashes in Gmail and Google+; ExLocator is capable of precisely locating the root causes of identified exceptions in real-world apps. Our substantial dataset is made publicly available to share with and benefit the community.
Generating texts of different sentiment labels is getting more and more attention in the area of natural language generation. Recently, Generative Adversarial Net (GAN) has shown promising results in text generation. However, the texts generated by GAN usually suffer from the problems of poor quality, lack of diversity and mode collapse. In this paper, we propose a novel framework – SentiGAN, which has multiple generators and one multi-class discriminator, to address the above problems. In our framework, multiple generators are trained simultaneously, aiming at generating texts of different sentiment labels without supervision. We propose a penalty based objective in the generators to force each of them to generate diversified examples of a specific sentiment label. Moreover, the use of multiple generators and one multi-class discriminator can make each generator focus on generating its own examples of a specific sentiment label accurately. Experimental results on four datasets demonstrate that our model consistently outperforms several state-of-the-art text generation methods in the sentiment accuracy and quality of generated texts.
Being the largest blockchain with the capability of running smart contracts, Ethereum has attracted wide attention and its market capitalization has reached 20 billion USD. Ethereum not only supports its cryptocurrency named Ether but also provides a decentralized platform to execute smart contracts in the Ethereum virtual machine. Although Ether’s price is approaching 200 USD and nearly 600K smart contracts have been deployed to Ethereum, little is known about the characteristics of its users, smart contracts, and the relationships among them. To fill in the gap, in this paper, we conduct the first systematic study on Ethereum by leveraging graph analysis to characterize three major activities on Ethereum, namely money transfer, smart contract creation, and smart contract invocation. We design a new approach to collect all transaction data, construct three graphs from the data to characterize major activities, and discover new observations and insights from these graphs. Moreover, we propose new approaches based on cross-graph analysis to address two security issues in Ethereum. The evaluation through real cases demonstrates the effectiveness of our new approaches.
The monolithic server model where a server is the unit of deployment, operation, and failure is meeting its limits in the face of several recent hardware and application trends. To improve heterogeneity, elasticity, resource utilization, and failure handling in datacenters, we believe that datacenters should break monolithic servers into disaggregated, network-attached hardware components. Despite the promising benefits of hardware resource disaggregation, no existing OSes or software systems can properly manage it. We propose a new OS model called the splitkernel to manage disaggregated systems. Splitkernel disseminates traditional OS functionalities into loosely-coupled monitors, each of which runs on and manages a hardware component. Using the splitkernel model, we built LegoOS, a new OS designed for hardware resource disaggregation. LegoOS appears to users as a set of distributed servers. Internally, LegoOS cleanly separates processor, memory, and storage devices both at the hardware level and the OS level. We implemented LegoOS from scratch and evaluated it by emulating hardware components using commodity servers. Our evaluation results show that LegoOS’s performance is comparable to monolithic Linux servers, while largely improving resource packing and failure rate over monolithic clusters.
The use of IR methodology in the evaluation of recommender systems has become common practice in recent years. IR metrics have been found however to be strongly biased towards rewarding algorithms that recommend popular items –the same bias that state of the art recommendation algorithms display. Recent research has confirmed and measured such biases, and proposed methods to avoid them. The fundamental question remains open though whether popularity is really a bias we should avoid or not; whether it could be a useful and reliable signal in recommendation, or it may be unfairly rewarded by the experimental biases. We address this question at a formal level by identifying and modeling the conditions that can determine the answer, in terms of dependencies between key random variables, involving item rating, discovery and relevance. We find conditions that guarantee popularity to be effective or quite the opposite, and for the measured metric values to reflect a true effectiveness, or qualitatively deviate from it. We exemplify and confirm the theoretical findings with empirical results. We build a crowdsourced dataset devoid of the usual biases displayed by common publicly available data, in which we illustrate contradictions between the accuracy that would be measured in a common biased offline experimental setting, and the actual accuracy that can be measured with unbiased observations.
We present the Succinct Range Filter (SuRF), a fast and compact data structure for approximate membership tests. Unlike traditional Bloom filters, SuRF supports both single-key lookups and common range queries: open-range queries, closed-range queries, and range counts. SuRF is based on a new data structure called the Fast Succinct Trie (FST) that matches the point and range query performance of state-of-the-art order-preserving indexes, while consuming only 10 bits per trie node. The false positive rates in SuRF for both point and range queries are tunable to satisfy different application needs. We evaluate SuRF in RocksDB as a replacement for its Bloom filters to reduce I/O by filtering requests before they access on-disk data structures. Our experiments on a 100 GB dataset show that replacing RocksDB’s Bloom filters with SuRFs speeds up open-seek (without upper-bound) and closed-seek (with upper-bound) queries by up to 1.5× and 5× with a modest cost on the worst-case (all-missing) point query throughput due to slightly higher false positive rate.
We give a constant-factor approximation algorithm for the asymmetric traveling salesman problem. Our approximation guarantee is analyzed with respect to the standard LP relaxation, and thus our result confirms the conjectured constant integrality gap of that relaxation.
Our techniques build upon the constant-factor approximation algorithm for the special case of node-weighted metrics. Specifically, we give a generic reduction to structured instances that resemble but are more general than those arising from node-weighted metrics. For those instances, we then solve Local-Connectivity ATSP, a problem known to be equivalent (in terms of constant-factor approximation) to the asymmetric traveling salesman problem.
As social agents, robots designed for human interaction must adhere to human social norms. How can we enable designers, engineers, and roboticists to design robot behaviors that adhere to human social norms and do not result in interaction breakdowns? In this paper, we use automated formal-verification methods to facilitate the encoding of appropriate social norms into the interaction design of social robots and the detection of breakdowns and norm violations in order to prevent them. We have developed an authoring environment that utilizes these methods to provide developers of social-robot applications with feedback at design time and evaluated the benefits of their use in reducing such breakdowns and violations in human-robot interactions. Our evaluation with application developers (N=9) shows that the use of formal-verification methods increases designers’ ability to identify and contextualize social-norm violations. We discuss the implications of our approach for the future development of tools for effective design of social-robot applications.
Text-based knowledge extraction methods for populating knowledge bases have focused on binary facts: relationships between two entities. However, in advanced domains such as health, it is often crucial to consider ternary and higher-arity relations. An example is to capture which drug is used for which disease at which dosage (e.g. 2.5 mg/day) for which kinds of patients (e.g., children vs. adults). In this work, we present an approach to harvest higher-arity facts from textual sources. Our method is distantly supervised by seed facts, and uses the fact-pattern duality principle to gather fact candidates with high recall. For high precision, we devise a constraint-based reasoning method to eliminate false candidates. A major novelty is in coping with the difficulty that higher-arity facts are often expressed only partially in texts and strewn across multiple sources. For example, one sentence may refer to a drug, a disease and a group of patients, whereas another sentence talks about the drug, its dosage and the target group without mentioning the disease. Our methods cope well with such partially observed facts, at both pattern-learning and constraint-reasoning stages. Experiments with health-related documents and with news articles demonstrate the viability of our method.
Carolina Cruz-Neira is a Spanish-Venezuelan-American computer engineer, researcher, designer, educator, and a pioneer of virtual reality (VR) research and technology. She is known for inventing the CAVE automatic virtual environment. She previously worked at Iowa State University (ISU), University of Louisiana at Lafayette and is currently the director of the Emerging Analytics Center at the University of Arkansas at Little Rock.
Ktask: optimizing CPU-intensive kernel work As a general rule, the kernel is supposed to use the least amount of CPU
time possible; any time taken by the kernel is not available for the
applications the user actually wants to run. As a result, not a lot of
thought has gone into optimizing the execution of kernel-side work requiring large
amounts of CPU. But the kernel does occasionally have to take on
CPU-intensive tasks, such as the initialization of the large amounts of
memory found on current systems. The ktask
subsystem posted by Daniel Jordan is an attempt to improve how the
kernel handles such jobs.
Fixing a Tough Memory Leak in Python We found our hard to diagnose Python memory leak problem in numpy and numba using C/C++. It turned out that the numpy array resulting from the above operation was being passed to a numba generator compiled in «nopython» mode. This generator was not being iterated to completion, which caused the leak.
CHP: Drunk driver slept while Tesla appeared to drive Hwy 101 on autopilot When a pair of California Highway Patrol officers pulled alongside a car cruising down Highway 101 in Redwood City before dawn Friday, they reported a shocking sight: a man fast asleep behind the wheel.
The car was a Tesla, the man was a Los Altos planning commissioner, and the ensuing freeway stop turned into a complex, seven-minute operation in which the officers had to outsmart the vehicle’s autopilot system because the driver was unresponsive, according to the CHP.
The arrest of 45-year-old Alexander Samek on suspicion of drunken driving reignited questions about the uses, and potential abuses, of self-driving technology.



 Bitcoin is now entering a death spiral, writes Atuyla Sarin.
Bitcoin is now entering a death spiral, writes Atuyla Sarin. Last week, the U.S. federal court ruled a case between the SEC and a crypto initial coin offering (ICO) project called Blockvest in favor of the project.
Last week, the U.S. federal court ruled a case between the SEC and a crypto initial coin offering (ICO) project called Blockvest in favor of the project.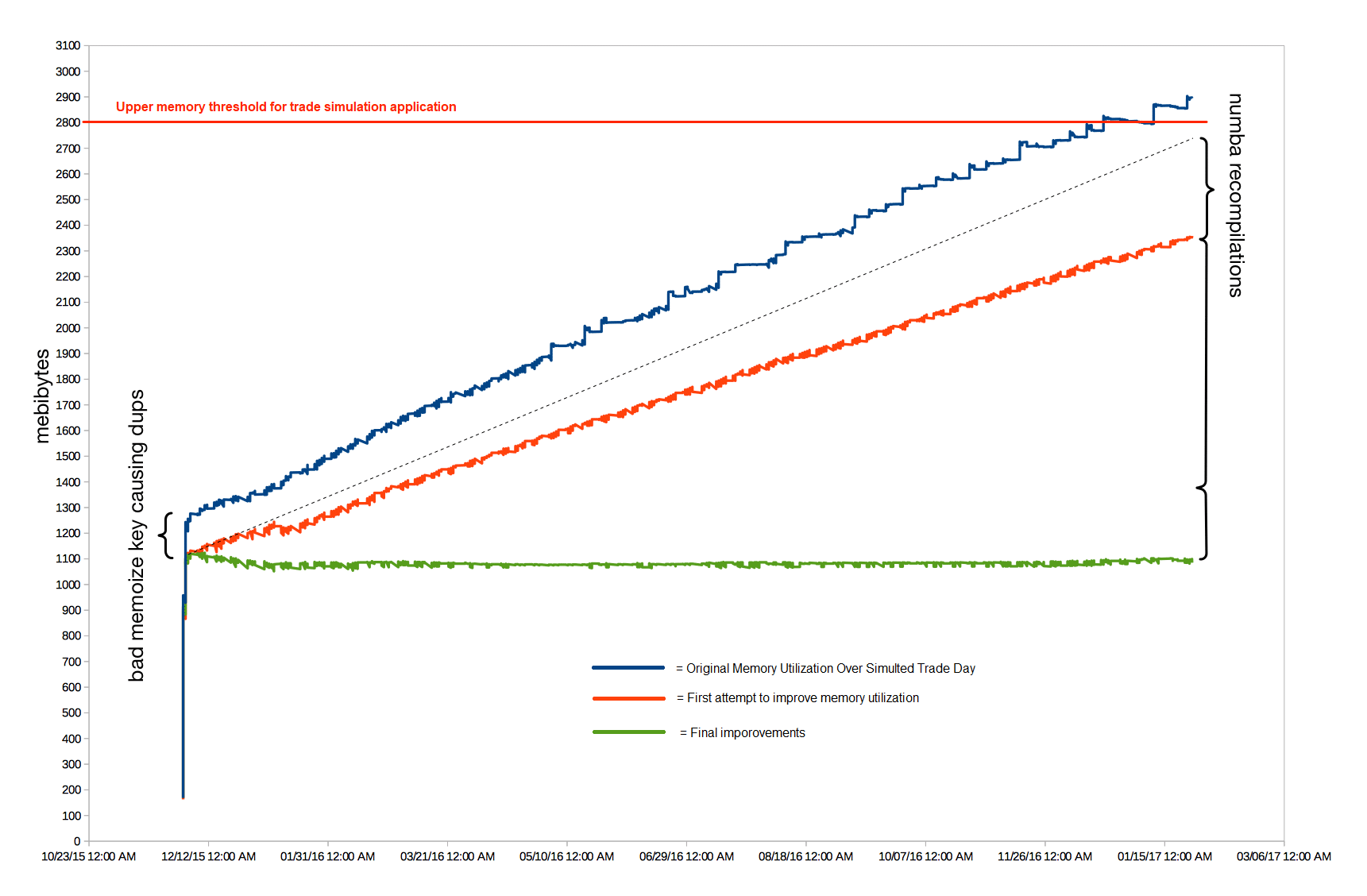 We found our hard to diagnose Python memory leak problem in numpy and numba using C/C++. It turned out that the numpy array resulting from the above operation was being passed to a numba generator compiled in «nopython» mode. This generator was not being iterated to completion, which caused the leak.
We found our hard to diagnose Python memory leak problem in numpy and numba using C/C++. It turned out that the numpy array resulting from the above operation was being passed to a numba generator compiled in «nopython» mode. This generator was not being iterated to completion, which caused the leak. When a pair of California Highway Patrol officers pulled alongside a car cruising down Highway 101 in Redwood City before dawn Friday, they reported a shocking sight: a man fast asleep behind the wheel.
When a pair of California Highway Patrol officers pulled alongside a car cruising down Highway 101 in Redwood City before dawn Friday, they reported a shocking sight: a man fast asleep behind the wheel. Monopolies are bad.
Monopolies are bad. Researchers have discovered that the so-called Rowhammer technique works on «error-correcting code» memory, in what amounts to a serious escalation.
Researchers have discovered that the so-called Rowhammer technique works on «error-correcting code» memory, in what amounts to a serious escalation.