
PROBLEMA
El cliente solicita la elaboración de dos apartados:
- Sistema de recomendación basado en Machine Learning
- Sistema de detección de tendencias
En la entrevista con el cliente se llega a la conclusión de que lo que en el fondo quiere es aumentar el tiempo de uso de la app y la recurrencia de uso: la retención.
Además, necesita comenzar a almacenar datos para posteriormente explotarlos.
PROPUESTA
Para el primer problema empezaría por implementar algunas estrategias que no requieren servicios externos, para así comenzar a tener datos y ver cuales de ellas son las que mejor funcionan. Por ejemplo:
- Al acabar una historia proponer de 1 a 3 recomendaciones: una random, otra random de la misma categoría, otra random del mismo autor.
- Si se incluyesen tags para afinar la categorización de las historias, incluiría una cuarta recomendación en el punto anterior.
- Cuando se abandona una historia preguntaría si se quiere guardar el progreso (y así saber si hay interés en ella).
- Gestionar el progreso que se lleva en cada historia.
- A las 6h, 12h, 24h, 48h del último uso lanzaría una notificación con texto del último párrafo leído de la última historia si se dejó a medias, o el primero de una recomendación del tipo que mejor esté funcionando para ese usuario (por categoría, autor, random, o tags si se implementan).
- Incluir fotos de los personajes y una vista de su perfil.
Todo esto se puede gestionar con facilidad desde la propia aplicación, y entendiendo que la empresa dispone de desarrolladores para esa parte, por el momento no se presupuestará.
Por petición del cliente se presupuesta la elaboración de un sistema de recomendación sin esperar a tener información previa de si las recomendaciones incrementarán sustancialmente el tiempo de uso y la recurrencia de la aplicación.
El sistema de recomendación estará basado en el algoritmo de machine learning k-means que busca los vecinos que se parecen al usuario actual para determinar cuáles son las historias que le podrían gustar, y es uno de los principales algoritmos empleados en los sistemas de recomendación.

Tal como hablamos en la visita realizada, es un sistema más similar al de Amazon que al de Netflix, ya que se tiene en cuenta el histórico del usuario individual. Este sistema tendrá en cuenta:
- Relatos que un usuario ya ha visto, para no volver a mostrarlos.
- Relatos que un usuario ha acabado, entendiendo que le han gustado.
- Relatos que un usuario ha abandonado, entendiendo que le han disgustado.
En base a esa información, buscará a los usuarios a los que les haya gustado y disgustado los mismos relatos que al usuario en cuestión, y en base a ellos obtendrá otros relatos que les hayan gustado y que el usuario actual no haya leído.
El algoritmo k-means es un algoritmo colaborativo similar al que usa Amazon, pero dado el bajo número de elementos del catálogo (cientos de millones frente a cientos) no se precisa una optimización de este para poder aplicarlo.
Para mitigar la falta de información con usuarios nuevos, se valorarán también otras variables que se pueden obtener desde el momento de instalación de la aplicación como son el modelo del terminal, la compañía proveedora de conexión, etc.
El sistema quedará preparado para que cuando se introduzcan valoraciones realizadas de manera consciente por los usuarios (like/dislike o puntuación), los cambios a realizar sean los menos posibles. En concreto, sólo habría que cambiar el servicio de ETL que convierta los eventos capturados en la matriz de votos.
Las tareas y componentes necesarios para este apartado, son los que constan en la tabla de precios como Comp. 2, puesto que al alimentarse del otro, debería de implementarse en segundo lugar. Los componentes principales de este sistema serán:
Servicio ETL que transforme la información de los eventos recibidos y la obtenida del catálogo de relatos en una matriz de valoraciones.
- Servicio de perfiles de usuario en base a variables del sistema.
- Servicio de preprocesado de matriz de valoraciones.
- Servicio de recomendación.
Para la captación de datos para su explotación, los principales actores son 3:
- Google Analytics. El problema que tiene es que en el momento que se quieren exportar datos se necesita la versión premium que tiene un coste de $150.000 USD al año.
- Mixpanel. Una solución de análisis que dispone de APIs para integrarla con cualquier sistema y poder exportar los datos. Su precio es de $999 USD al año. Es una buena solución siempre que no se vuelva poco flexible, ya que a la larga te tienes que amoldar a sus posibilidades.
- Una solución a medida que permita guardar cuantos datos se desee en el formato que se prefiera, para que posteriormente se les puedan dar distintos tratamientos para obtener distintas informaciones ya sean en modo de servicio para proveer de nuevas funcionalidades a la aplicación, informes, datos tratados para su venta. Es una buena solución en cuanto a relación flexibilidad y coste.
Dado que las dos primeras opciones sólo requieren realizar modificaciones en la aplicación, se presupuestará sólo la tercera.
A partir de tener los datos almacenados mediante cualquiera de los sistemas, posteriormente se podrán tratar para cubrir cualesquiera necesidades surjan:
- Obtener perfil de uso y progreso de un usuario.
- Obtener recomendaciones a medida de un usuario.
- Creación de informes.
- Búsqueda de patrones de comportamiento.
- Envío de notificaciones personalizadas.
- Etc.
CONCEPTO
Elaboración de un servicio que reciba datos para identificación del dispositivo/usuario y una colección de eventos (1..N) para almacenar todas las acciones que haya realizado el usuario. El paso de datos se hará en formato JSON de tal modo que la definición de la estructura pueda ir variando con el tiempo sin necesidad de modificar el servicio.
El hecho de permitir mandar varios eventos, permitirá que no se pierda información cuando la aplicación se use offline. Además permitirá no estar realizando comunicaciones constantes si por ejemplo se decide registrar cada uno de los “scroll” que se hacen en las historias para seguir leyendo, pudiendo guardarse cada 10 scrolls por ejemplo.
A petición del cliente se usaría Azure.
Se propone para la computación usar Azure Functions, ya que permite que el sistema escale de manera automática y no pagar nada cuando no hay uso del servicio.
Para el almacenamiento se sugiere el uso de Azure Cosmos DB, una base de datos orientada a documentos, que permite almacenar cualquier tipo de estructura de datos, pudiendo cambiarse esta sobre la marcha, permitiendo así introducir nuevos datos que se haya visto con el uso que pueden ser útiles.
PRECIO
| Nº | Tarea | Comp. | Precio |
| 1 | Preparación de sistemas | 1 | 400,00€ |
| 2 | Creación servicio | 1 | 1.400,00€ |
| 3 | Pruebas de carga | 1 | 300,00€ |
| 4 | Documentación | 1 | 300,00€ |
| 5 | Migración a sistemas cliente | 1 | 400,00€ |
| Subtotal | 1 | 2.800,00€ | |
| 6 | Preparar BBDD | 2 | 400,00€ |
| 7 | Servicio ETL | 2 | 1.200,00 |
| 8 | Servicio perfiles | 2 | 900,00 |
| 9 | Servicio de preprocesado | 2 | 1.800,00 |
| 10 | Servicio de recomendación | 2 | 1.500,00 |
| Subtotal | 2 | 5.800,00€ | |
| TOTAL | 8.600,00€ | ||
TIEMPOS
El componente tiene una estimación de 1 (un) mes. El segundo componente tiene una estimación de 2 (dos) meses, si bien se podría acortar el tiempo de desarrollo a la mitad incrementando el presupuesto de dicho componente en un 30%. El tiempo total de desarrollo del proyecto, por tanto, sería de 3 (tres) meses.
Nota aclaratoria:
Este proyecto tipo, es un ejemplo de proyecto que se ha realizado o se podría realizar. En ningún caso tiene validez como presupuesto real y sólo pretende documentar las distintas posibilidades que existen.
Actualmente, con los cambios que ha habido en cuanto a las posibilidades existentes, la propuesta habría sido distinta.
Se han omitido nombres de empresas y productos.
Por favor, si tuviese necesidad de algo similar, no dude en ponerse en contacto.
 Se trata de montar un servidor con el servicio Nominatim y mapas de América Central. Para lo cual el cliente proporcionará un servidor con las siguientes características mínimas:
Se trata de montar un servidor con el servicio Nominatim y mapas de América Central. Para lo cual el cliente proporcionará un servidor con las siguientes características mínimas:

 Bitcoin is now entering a death spiral, writes Atuyla Sarin.
Bitcoin is now entering a death spiral, writes Atuyla Sarin. Last week, the U.S. federal court ruled a case between the SEC and a crypto initial coin offering (ICO) project called Blockvest in favor of the project.
Last week, the U.S. federal court ruled a case between the SEC and a crypto initial coin offering (ICO) project called Blockvest in favor of the project.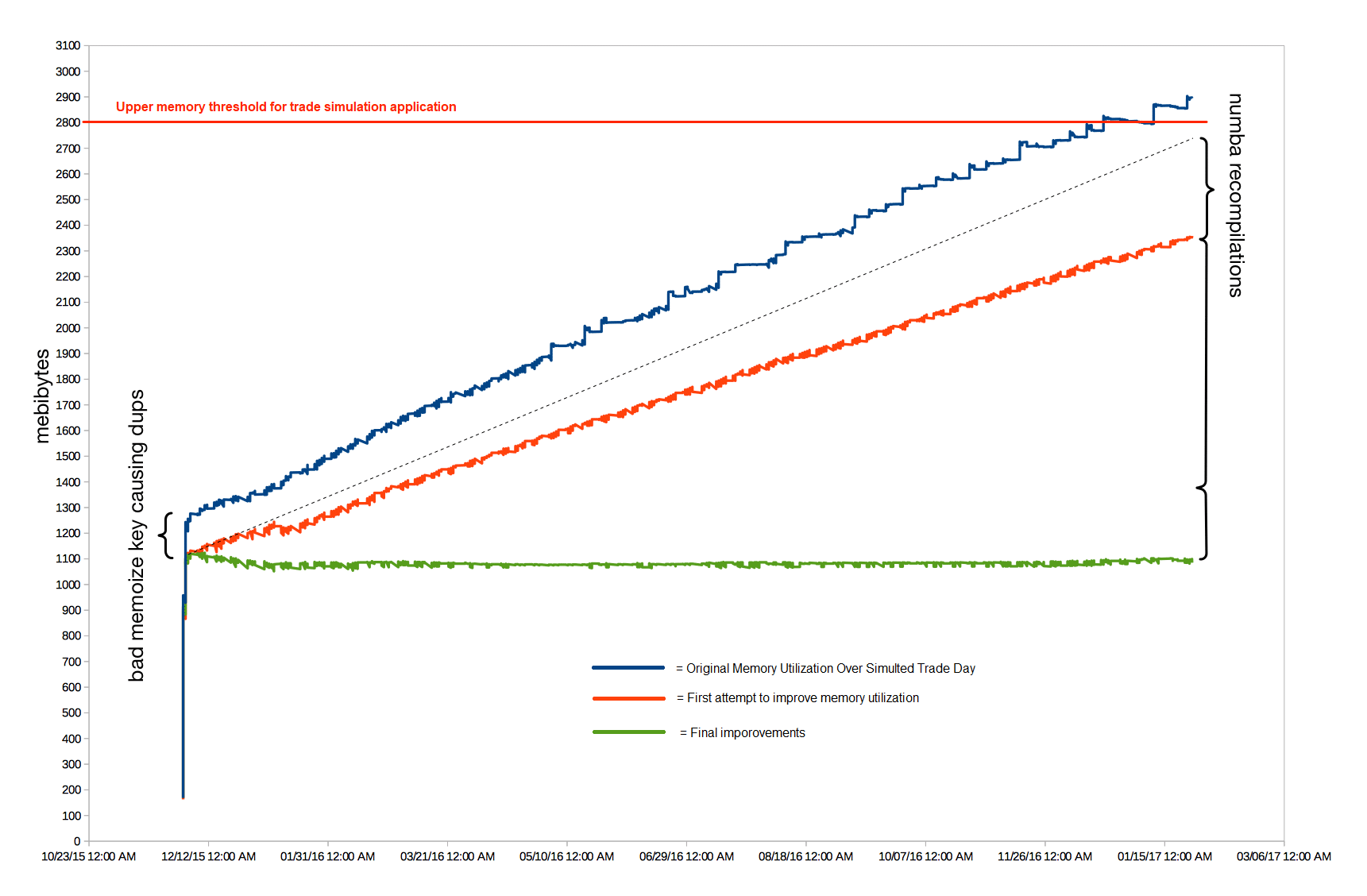 We found our hard to diagnose Python memory leak problem in numpy and numba using C/C++. It turned out that the numpy array resulting from the above operation was being passed to a numba generator compiled in «nopython» mode. This generator was not being iterated to completion, which caused the leak.
We found our hard to diagnose Python memory leak problem in numpy and numba using C/C++. It turned out that the numpy array resulting from the above operation was being passed to a numba generator compiled in «nopython» mode. This generator was not being iterated to completion, which caused the leak. When a pair of California Highway Patrol officers pulled alongside a car cruising down Highway 101 in Redwood City before dawn Friday, they reported a shocking sight: a man fast asleep behind the wheel.
When a pair of California Highway Patrol officers pulled alongside a car cruising down Highway 101 in Redwood City before dawn Friday, they reported a shocking sight: a man fast asleep behind the wheel. Monopolies are bad.
Monopolies are bad. Researchers have discovered that the so-called Rowhammer technique works on «error-correcting code» memory, in what amounts to a serious escalation.
Researchers have discovered that the so-called Rowhammer technique works on «error-correcting code» memory, in what amounts to a serious escalation.