Chatbots, conversational interfaces, that started their hype two years ago are really funny but they aren’t always useful. Design a conversation having in mind all different possible options needs a lot of effort. Is it necessary to manage all possible inputs in order to manage a simple business task? Thinking about most of the apps, the answer is «no», else we wouldn’t have a lot of apps based on forms getting information to do something.

Microsoft gives us, inside Bot Framework, an easy way to model tiny business functionalities that in other environments we would resolve using a simple form. FormFlow is an engine that, using a data model, can automatize a conversation to get all the information needed to fill the model and allow us to do whatever we want with the data.
Thanks to it we can use the omnipresence of chatbots to be more near to our public (because chatbots are in a lot of channels in which users are already present).
Let’s go to see how we can deploy a simple chatbot inside Azure. You will see that using FormFlow is so easy so we don’t need to open Visual Studio to code it. It will be like magic! We are going to do an emulator of the Sorting Hat from Hogwarts who decided, in J. K. Rowling stories, to what house the students of the school of magic were going.
It is a really easy example, but full of functionalities and details, that is going to be useful as a base to make any simple app that needs to get some data with which do something: calculate something (like in this case but also it could be calculating a loan conditions or the price for a car insurance), call to an API (for instance in order to record a request for a loan, or to request a call from a salesperson), or whatever comes to mind.
As most of the bot is based on the data model definition it will be an easy task no matter how complex it was, because the magic is coded by Microsoft inside FormFlow.
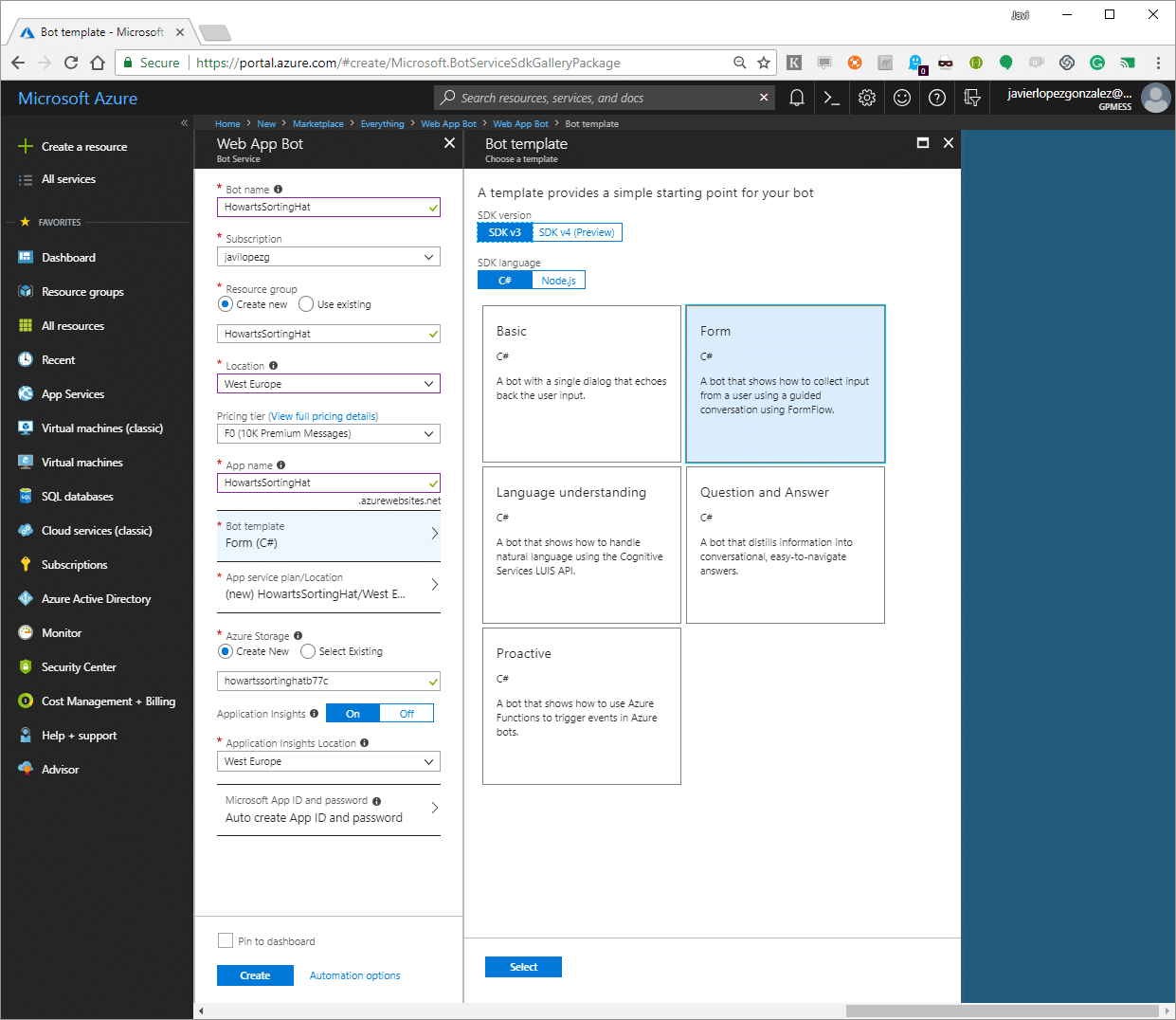
Our first move has to be creating a new bot over Azure (Web App Bot). To get the easy way, let’s use an example bot, so when we are creating the app we will tell to Azure that has to use the FormFlow template.
When it was deployed, we will have two elements with the same name: a Web App and the Web App Bot. Inside the Web App Bot options, we can find one (under Build menu) to edit code online, that’s the one that we will use to edit our bot’s code because it’s so simple that we don’t need to do complex things.
Bots based on FormFlow use a model, so we have to define one. Our Sorting Hat isn’t so magic like the one from Hogwarts, ours gets information from students in order to take a decision.
Fields of our model can be from basic types (integers, floating point numbers, strings, DateTimes, enumerations) and lists of enumerations. In our case, we will start only with enumerations because values that we will manage are too specific to our domain.
public enum Nombres {
Godric,
Helga,
Rowena,
Salazar
};
public enum Cualidades {
Valentía,
Honestidad,
Inteligencia,
Ambición
};
public enum Colores {
Rojo,
Amarillo,
Azul,
Verde
};
public enum ColoresDeJoyas {
Oro,
Negro,
Bronce,
Plata
};
public enum Animales {
Leon,
Tejon,
Aguila,
Serpiente
};
public enum LugaresParaVivir {
TorreOscura,
Bodega,
TorreLuminosa,
Mazmorras
};
public enum Titulos {
Sir,
Fraile,
Dama,
Barón
};
public enum Amigos {
Ron,
Neville,
Hermione,
Harry
};
public enum Accesorios {
Espada,
Copa,
Diadema,
Guardapelo
}
[Serializable]
public class SortingTest
{
public Nombres? Nombre;
public Cualidades? Cualidad;
public Colores? Color;
public ColoresDeJoyas? ColorDeJoyas;
public Animales? Animal;
public LugaresParaVivir? LugarParaVivir;
public Titulos? Titulo;
public Amigos? Amigo;
public Accesorios? Accesorio;
public static IForm<SortingTest> BuildForm()
{
OnCompletionAsyncDelegate<SortingTest> evaluate = async (context, state) =>
{
await context.PostAsync(“OK”);
};
return new FormBuilder<SortingTest>()
.Message(“Hola”)
.OnCompletion(evaluate)
.Build();
}
};
If you also want to manage new information like the name or the birth date, you only need to add new properties to our model that bot will manage and validate for you.
public string TuNombre;
public DateTime? FechaDeNacimiento;
As soon as we have our class model defined, we only have to add this to our project creating an online file and we can also delete the example model that is not related to our magic world.
 We also have to do some minor changes in the controller to allow it use our new model instead of the one we deleted. The file name is MessagesController.cs and we will change references to the model on MakeRootDialog method.
We also have to do some minor changes in the controller to allow it use our new model instead of the one we deleted. The file name is MessagesController.cs and we will change references to the model on MakeRootDialog method.
internal static IDialog<SortingTest> MakeRootDialog()
{
return Chain.From(() => FormDialog.FromForm(SortingTest.BuildForm));
}
From this point, we can compile (build.cmd) and test our bot. Again, inside Web App Bot options we have one to test our bot using a web client without leaving Azure Portal. As soon as we say «Hi» it will answer us and we could see it asking us to fill the model.
 When we are capturing all the data, we only have to process that and to do this we will change code inside BuildForm method of our SortingTest. If we test it again, we will see that we already have all working. However, it’s not very beautiful that if our bot is made for Spanish speakers it speaks in English. FormFlow is ready to localize it to different languages but in our case only will change some details using attributes over our model.
When we are capturing all the data, we only have to process that and to do this we will change code inside BuildForm method of our SortingTest. If we test it again, we will see that we already have all working. However, it’s not very beautiful that if our bot is made for Spanish speakers it speaks in English. FormFlow is ready to localize it to different languages but in our case only will change some details using attributes over our model.
There are attributes for many things. For instance, we can set optional fields or create our very own validations. We will use a template attribute to change the question that is made for each field.
[Template(TemplateUsage.EnumSelectOne, "Elige un {&} {||}", ChoiceStyle = ChoiceStyleOptions.Auto)]
There is a full language to edit messages format. In our case, {&} characters represent the field name and {||} characters different options for the user. The ChoiceStyleOptions enumeration allows us to indicate how options are shown.
If we would test again we will see that it is more elegant, but it is not elegant at all because of some language conflicts. For instance «Cualidad» is female and the question is not neutral so it’s not well-formed for female names. It’s the same for string and DateTime properties for what we didn’t change their template. We can use a similar attribute that is applied to one only property.
[Prompt("Elige una cualidad {||}")]
FormFlow has more capabilities but with these, we could do some «tech magic» in few minutes to get something beautiful and functional. We only have to select one or more channels to publish it to start reaching our public just in the channel they are working daily. For instance, if you want to know what the Sorting Hat is thinking about you, you only have to visit javilopezg.com/SortingHat and talk to it.